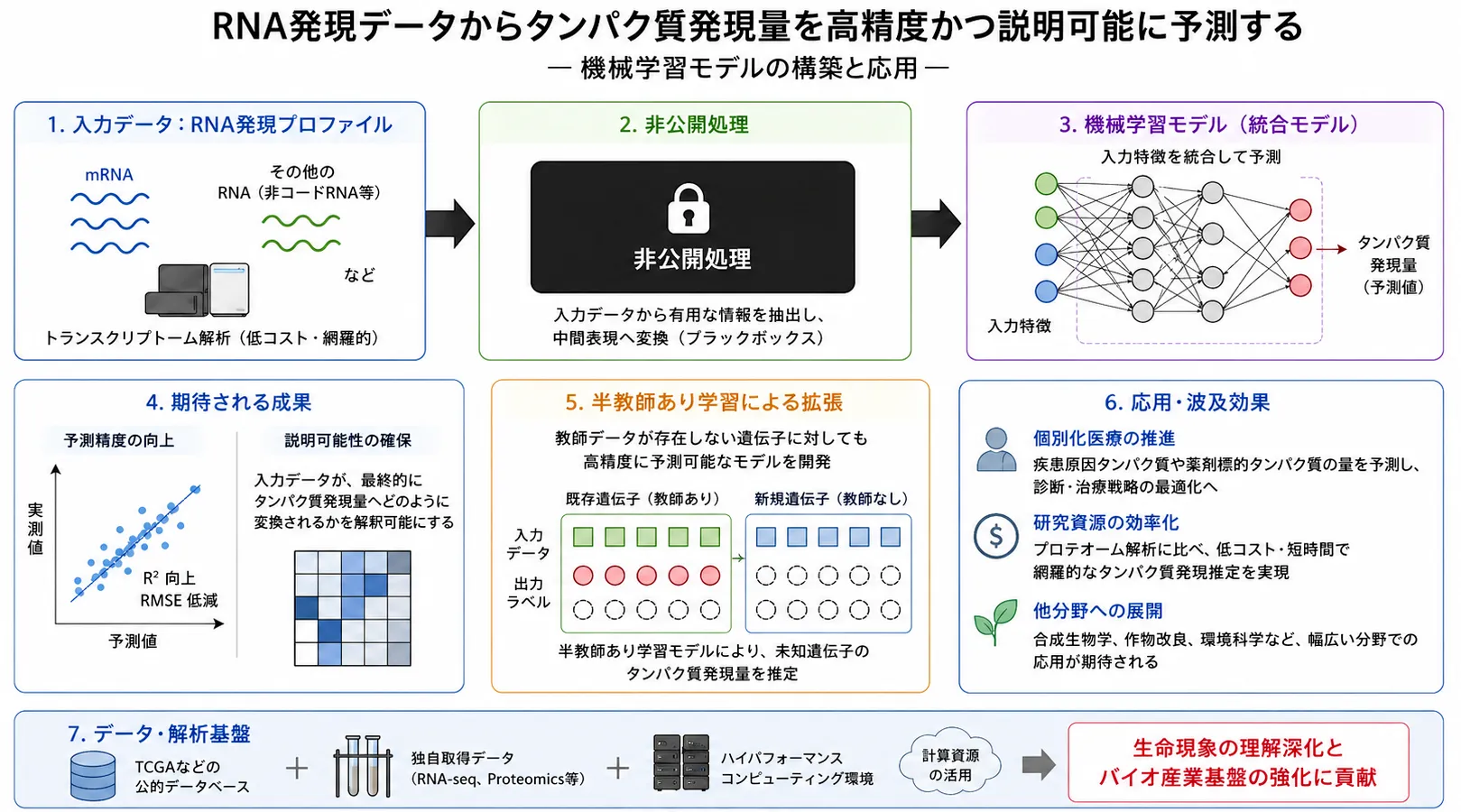
RNAからタンパク質を予測する
取得しやすいRNA発現データから、生命機能を直接担うタンパク質発現量を推定します。
RNA発現データからタンパク質発現量を推定することは、生命現象の理解、個別化医療、創薬、合成生物学、バイオ産業の基盤技術として重要です。
本研究では、ある要素Xをニューラルネットワークに組み込み、予測精度と説明可能性を両立する機械学習モデルの開発を目指します。
生命現象を直接担う主要な分子はタンパク質ですが、プロテオーム解析はコスト、簡便性、網羅性の面で制約があります。
そのため、多くの基礎研究や応用研究では、取得しやすいトランスクリプトームデータが利用されています。
しかし、mRNA発現量はタンパク質量の完全な代理指標ではなく、RNA発現量からタンパク質発現量を高精度に予測することは依然として難しい課題です。
この難しさの一因として、miRNAやlncRNAなどの非翻訳RNAによる翻訳抑制、翻訳活性化、RNA間相互作用、
転写後制御などが複雑に関与していることが考えられます。
本研究では、ある要素Xを機械学習モデルの構造に反映させることで、説明可能な形で予測することを目指します。
本研究の中心にある問いは、
「ある要素Xを数理モデル化することで、RNA発現量からタンパク質発現量を説明および予測できるのか」
というものです。
従来の機械学習モデルは、予測性能を高められる一方で、モデル内部の構造や重みを生物学的に解釈しにくいという問題があります。
本研究では、ある要素Xそのものをニューラルネットワークの構造に組み込むことで、
予測結果の根拠を説明できるモデルを目指します。
取得しやすいRNA発現データから、生命機能を直接担うタンパク質発現量を推定します。
ある要素Xを、予測モデルの構造に反映させます。
ブラックボックス的な予測ではなく、生物学的意味づけが可能な機械学習モデルを構築します。
タンパク質発現量の教師データが存在しない遺伝子に対しても、半教師あり学習により予測を試みます。
本研究の最大の特徴は、ある要素Xをニューラルネットワークに組み込む点にあります。
これにより、従来法で課題となっていた「高精度だが解釈しにくいモデル」と、
「解釈しやすいが表現力に限界があるモデル」の間をつなぐ、説明可能な予測モデルを構築します。
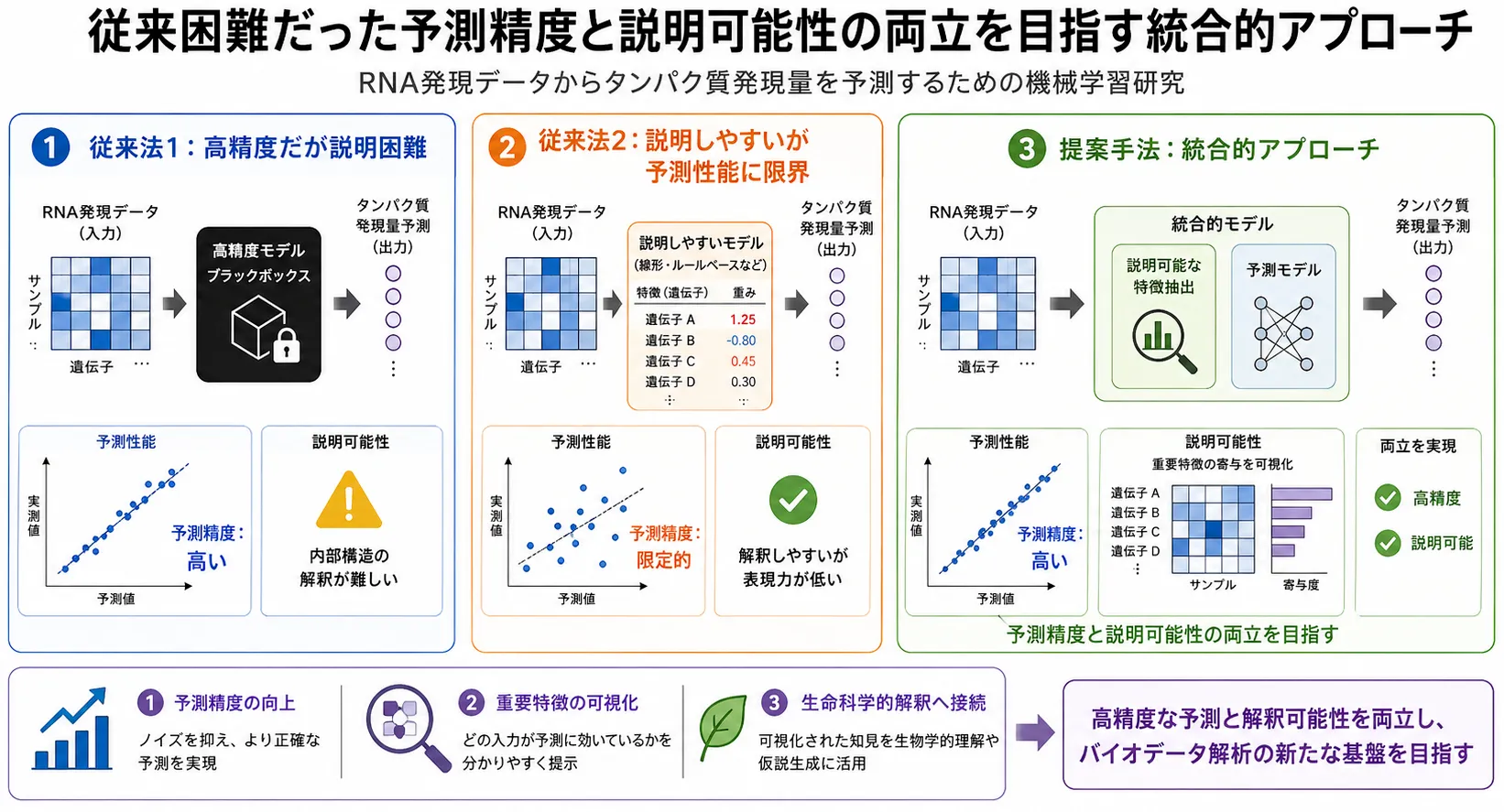
本研究では、公共データベースや独自に取得するデータを用いて、RNA発現量とタンパク質発現量の関係を解析します。
まず教師データが存在する遺伝子について予測精度を高め、その後、タンパク質発現量の正解データが存在しない遺伝子にも対応できるよう、
半教師あり学習の回帰モデルへ拡張します。
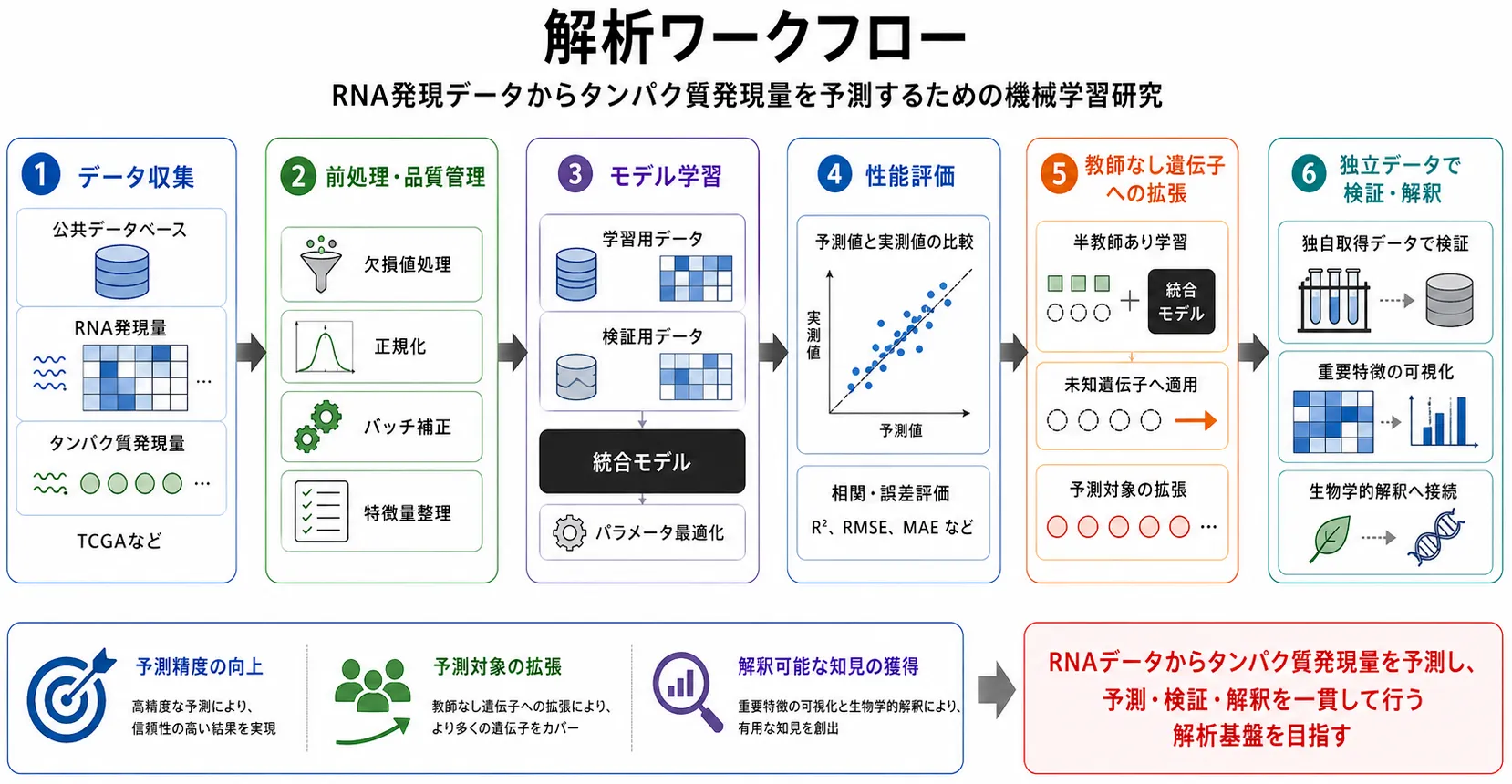
本研究では、説明可能なニューラルネットワークによって、教師データが存在する遺伝子だけでなく、
教師データが存在しない遺伝子についてもタンパク質発現量を予測できるかを検証します。
具体的には、教師データがある遺伝子ではより高精度な予測を、教師データがない遺伝子では半教師あり学習による予測可能性の実証を目指します。
パラメータ調整、活性化関数の最適化、ネットワーク構造の改良により、既存モデルを上回る予測精度を目指します。
半教師あり学習を回帰問題へ拡張し、正解データがない遺伝子のタンパク質発現量予測に挑戦します。
予測に寄与するある要素Xを抽出し、解釈できる形で整理します。
公共データと独自取得データを組み合わせ、モデルの汎化性能と生物学的妥当性を検証します。
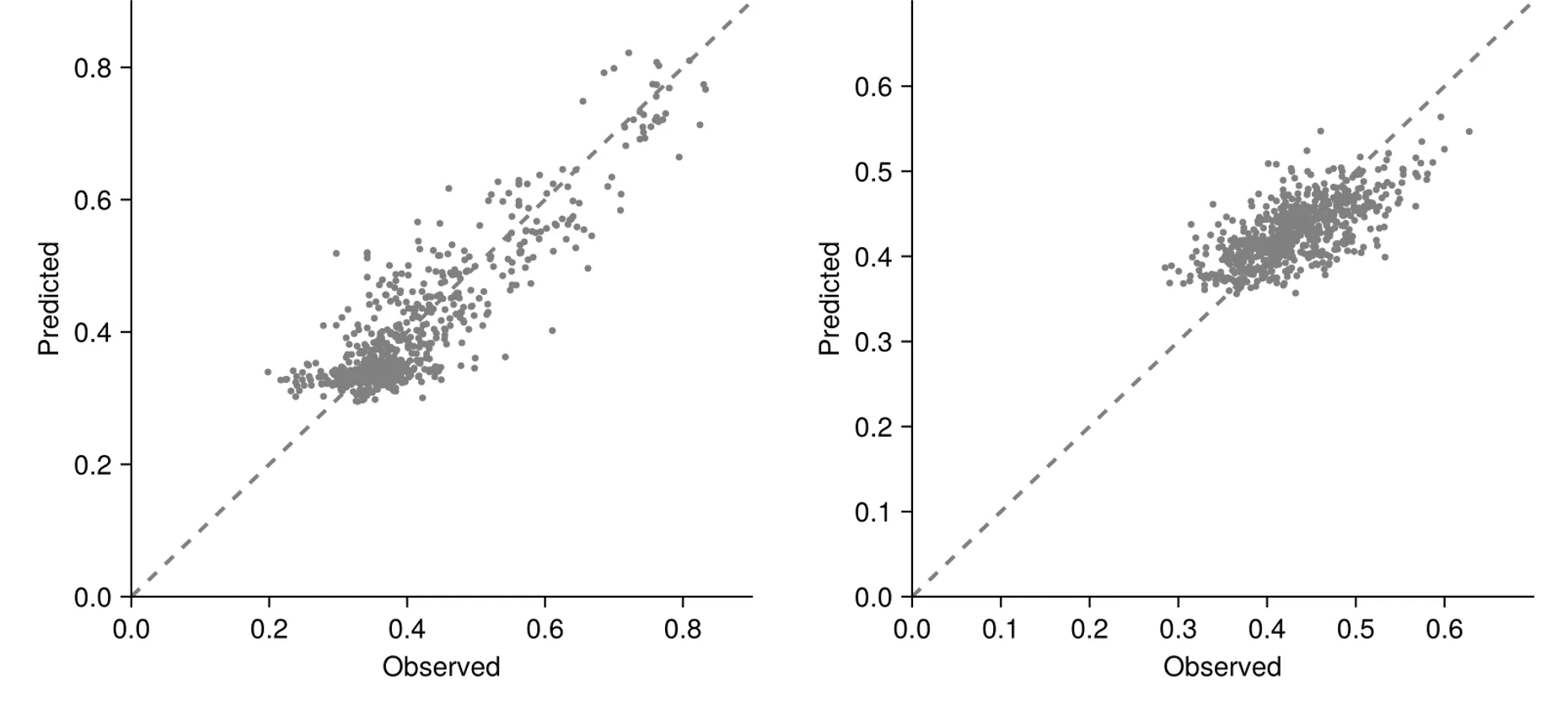
予備研究では、ある要素Xを組み込んだ簡易モデルを構築し、RNA発現量からタンパク質発現量を予測できる可能性を確認しました。
その結果、全遺伝子の一部で高精度な予測が得られ、多くの遺伝子で予測値と実測値の有意な相関が確認されました。
一方で、この簡易モデルでは教師データが存在しない遺伝子を十分に扱えないという制約があり、
本研究ではその制約を克服するためにモデルを拡張します。
RNA発現量からタンパク質発現量を低コストかつ網羅的に推定できるようになれば、基礎生命科学だけでなく、
個別化医療、創薬、合成生物学、生物工学、環境科学など多くの分野への展開が期待されます。
特に、患者ごとのRNA発現プロファイルから疾患原因タンパク質や薬剤標的タンパク質の量を推定できれば、
診断や治療戦略の選択を支援する新しい情報基盤になります。
本研究では、TCGAなどの公共データベースに加えて、必要に応じて新規データの収集も行います。
また、モデル学習にはGPUを搭載した高性能計算環境を用い、データ前処理からモデル学習、検証までを一貫して実行できる解析基盤を活用します。